Somewhere between the realms of science fiction and cutting-edge computer science lies a force that has quietly infiltrated our daily lives, powering everything from voice assistants to medical diagnostics, from fraud detection to autonomous cars. This force is deep learning, a subset of artificial intelligence (AI) that mimics the human brain’s structure and function to perform astonishingly complex tasks. It learns patterns, understands languages, recognizes faces, generates art, and beats humans in games we invented. But beneath the surface of its miraculous abilities lies a deep and intricate structure—a framework known as the deep learning algorithm.
The phrase “deep learning algorithm” often floats around in tech discussions like a buzzword from a sci-fi script. But in truth, it is the core of a revolution that is transforming industries, challenging philosophical notions of intelligence, and rewriting what machines are capable of doing. To truly grasp what the deep learning algorithm is, we need to journey into the architecture of artificial neural networks, the mechanics of learning, and the complex interplay of data and computation.
The Inspiration: Borrowing From Biology
It’s fascinating to realize that deep learning didn’t start in a lab filled with servers—it started with neurons in the human brain. In the mid-20th century, scientists began to speculate whether machines could emulate the brain’s ability to learn. The neuron, a microscopic yet mighty component of the nervous system, became the biological muse for a new breed of computer algorithms.
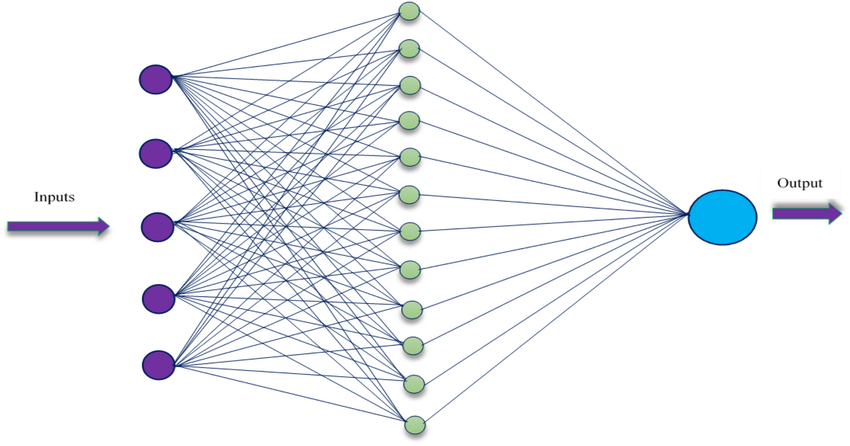
Neurons in the brain communicate through electrical signals. Each neuron receives inputs from others, processes them, and decides whether to pass the signal along. This mechanism inspired the creation of the artificial neuron, a simple mathematical model that receives inputs, applies weights, sums them up, and passes the result through an activation function. Alone, this artificial neuron is limited. But when you link thousands—or millions—of them together in layers, you create a neural network capable of powerful pattern recognition.
This structure is the backbone of deep learning. The term “deep” refers to the multiple layers of neurons stacked between the input and the output. The more layers, the deeper the network—and the more abstract the concepts it can learn. The deep learning algorithm governs how this network processes information and adjusts itself to improve performance.
Data: The Fuel That Feeds Deep Learning
Without data, a deep learning algorithm is just an inert scaffold of math. But once you feed it data, it begins to come alive.
Imagine you’re training a deep learning model to recognize cats in images. You don’t program it with rules like “look for pointy ears” or “check for whiskers.” Instead, you show it thousands—perhaps millions—of labeled images of cats and non-cats. Each image passes through the neural network, activating neurons in different layers based on its content. The network’s initial guesses will be laughably wrong, but here’s where the magic begins: it learns from its mistakes.
Using a method called backpropagation, the network compares its output with the actual label (e.g., “cat” or “not cat”), calculates the error, and then adjusts the internal weights of its neurons to reduce that error. This process is repeated over and over, each time refining the network’s internal parameters until it can recognize cats with remarkable accuracy—often better than humans.
The more data you feed it, the more nuanced its understanding becomes. This dependency on massive datasets is both a strength and a limitation of deep learning. It excels when there’s a sea of data to learn from—but struggles when examples are few and far between.
Layers of Intelligence: Understanding Network Architecture
To understand how deep learning algorithms actually work, it’s useful to explore the architecture of the networks they use. At the base is the input layer, where data enters the system. If you’re working with images, this layer might take pixel values; for audio, it might accept sound wave amplitudes.
Next come the hidden layers—often several in a deep network—where the real processing happens. These layers extract increasingly abstract features from the data. In an image recognition task, the early layers might detect edges and colors, while the deeper layers recognize shapes, eyes, and eventually entire cats.
The final layer is the output layer, which produces a prediction. This could be a category label, a numerical value, or even a complete sentence, depending on the task. The behavior of each layer is governed by weights (which influence how strongly input values are passed through) and activation functions (which determine whether a neuron “fires” or not).
Deep learning algorithms use this layered approach to detect patterns that are too complex or subtle for traditional algorithms. That’s why they’re ideal for tasks like natural language understanding, image recognition, and game playing—problems where clear rules are hard to define, but patterns are abundant.
The Art of Training: Learning to Learn
Training a deep learning algorithm is both an art and a science. The process begins by initializing the network’s weights—typically with small random values. Then comes the forward pass, where input data flows through the network and produces an output. This output is compared to the correct answer using a loss function, a mathematical tool that quantifies how wrong the network’s prediction is.
Now comes the backward pass, where the algorithm calculates how each weight in the network contributed to the error. This is achieved using a clever application of calculus known as the chain rule, which allows for efficient computation of gradients. These gradients tell the network how to tweak each weight to reduce the error.
The weights are updated using a technique called gradient descent—a process of making small adjustments in the direction that reduces the loss. This cycle of forward pass, error calculation, backward pass, and weight update is repeated thousands or millions of times until the network’s predictions become accurate.
But training isn’t just about running the algorithm—it requires choices and optimizations. How many layers should the network have? How many neurons per layer? Which activation function should be used? What learning rate should be set? These parameters can dramatically affect performance and are often tuned through experimentation or automated processes known as hyperparameter optimization.
Types of Deep Learning Models
Different problems require different types of deep learning models, and over the years, researchers have developed specialized architectures for specific tasks. The most well-known is the Convolutional Neural Network (CNN), designed primarily for image-related tasks. CNNs use a mathematical technique called convolution to extract spatial features from images, making them extremely efficient and accurate in visual recognition.
Then there are Recurrent Neural Networks (RNNs) and their improved cousin, the Long Short-Term Memory (LSTM) networks, which are built to handle sequences of data. These models excel in tasks like language modeling, speech recognition, and time-series forecasting, where the order of the input data matters.
In recent years, Transformers have taken center stage, especially in natural language processing. Unlike RNNs, transformers don’t process data sequentially. Instead, they use a mechanism called self-attention to weigh the importance of different words or elements in a sequence, enabling them to understand context better. Transformers power models like BERT, GPT, and ChatGPT—models that can generate human-like text, summarize articles, translate languages, and more.
Each architecture has its strengths and trade-offs, and the choice of model depends on the specific problem at hand, the size of the data, and the desired outcome.
Challenges and Limitations
Despite its incredible potential, deep learning is far from perfect. One of its main limitations is the requirement for large datasets. Unlike humans, who can learn from just a few examples, deep learning models typically need thousands—or even millions—of labeled examples to perform well.
They’re also prone to overfitting, where a model becomes too good at memorizing the training data but performs poorly on new, unseen data. Techniques like dropout, data augmentation, and regularization are used to combat this, but the problem persists.
Another challenge is interpretability. Deep learning models are often considered “black boxes” because their internal workings are difficult to interpret. While they may produce accurate results, understanding why they made a certain decision is often opaque. This poses ethical and legal concerns, especially in fields like healthcare, finance, and criminal justice, where transparency is crucial.
Moreover, deep learning models can be computationally expensive, requiring vast amounts of processing power and energy. Training a large model can take days or weeks on specialized hardware like GPUs or TPUs, and running them in real-time applications requires robust infrastructure.
Deep Learning in the Real World
Despite these challenges, deep learning has made its mark across a variety of industries. In healthcare, it’s helping radiologists detect tumors, analyze DNA sequences, and predict disease outbreaks. In finance, it’s used to detect fraud, forecast markets, and power robo-advisors.
In entertainment, deep learning algorithms personalize content on streaming platforms, recommend songs, and even create music or visual art. In autonomous vehicles, they interpret sensory data to make split-second decisions about navigation and safety.
Retailers use it for customer segmentation, inventory optimization, and demand forecasting. Governments deploy it in surveillance and security. Environmental scientists use it to monitor climate change and track endangered species.
The list goes on—and it’s growing every day. Deep learning is not just a tool; it’s becoming an essential component of modern infrastructure.
The Future: Towards Artificial General Intelligence?
Many experts see deep learning as a stepping stone toward Artificial General Intelligence (AGI)—a machine that can perform any intellectual task a human can. Today’s deep learning algorithms are narrow; they excel in specific domains but falter outside them. A model trained to play chess can’t drive a car or write poetry.
But with advancements in architectures, transfer learning, unsupervised learning, and reinforcement learning, we’re inching closer to models that can adapt, reason, and generalize across tasks. Multimodal models—those that can understand text, images, and sound—are already showing early signs of broader intelligence.
Still, AGI remains a distant goal, wrapped in ethical dilemmas and philosophical questions. Should we build machines that think like humans? What rights would such machines have? Who bears responsibility for their actions?
These are the questions the next generation will face—and deep learning algorithms will undoubtedly be at the center of the debate.
Conclusion: A Glimpse Into the Machine Mind
The deep learning algorithm is not just a marvel of mathematics and computation—it is a mirror reflecting our own cognition. By trying to teach machines to learn, we have discovered new insights into how we ourselves learn, think, and understand.
It has already transformed our world, often invisibly, quietly altering the way we work, communicate, and live. From your smartphone unlocking with your face, to your voice assistant scheduling meetings, to medical systems diagnosing conditions more accurately than ever before—the reach of deep learning is profound and growing.
Yet we are only scratching the surface. As researchers push boundaries and machines grow smarter, the deep learning algorithm will continue to evolve. It is not just a tool for automation; it is a creative force, a scientific instrument, and perhaps even a new form of intelligence in its own right.
To understand deep learning is to glimpse the architecture of machine thought. And in doing so, perhaps we come a little closer to understanding ourselves.





