In the grand theater of technology, few revolutions have been as profound, as invisible, and as inevitable as machine learning. Like unseen gears powering the clockwork of modern life, machine learning drives everything from recommendation systems suggesting your next binge-worthy series, to voice assistants interpreting your commands, to autonomous cars navigating complex traffic.
But within this broad domain, two fundamental paradigms stand at the center of machine learning’s powerful engine: supervised learning and unsupervised learning. These two methods differ not just in technique, but in philosophy. They shape how machines see the world, how they learn, and how they act.
To truly appreciate the marvel of machine learning, we must delve into these two pillars. We must ask: How do machines learn with a teacher versus without one? How do they find structure in chaos? What can these different approaches achieve? And what does it all mean for the future?
Let’s journey deep into the heart of supervised and unsupervised learning—past the buzzwords, past the algorithms—into the essence of intelligent systems.
Supervised Learning: When Machines Learn With a Guide
The Essence of Supervised Learning
Imagine a student sitting in a classroom, being taught how to solve math problems. The teacher provides questions and correct answers. The student practices, makes mistakes, receives corrections, and gradually improves.
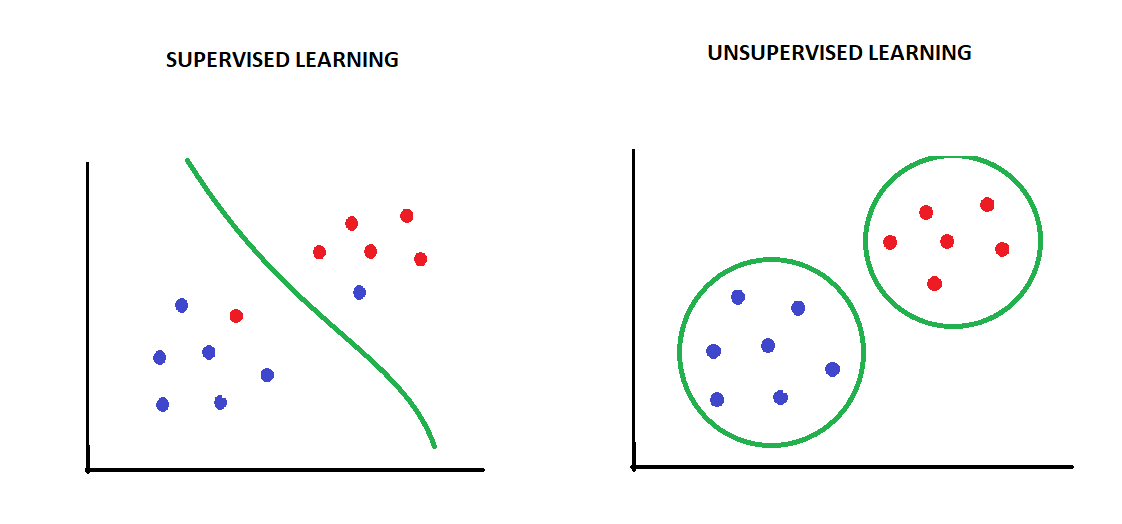
This is the core idea behind supervised learning. In supervised learning, we provide the machine with a labeled dataset—inputs paired with correct outputs. The machine’s task is to learn the mapping from input to output so accurately that it can predict the output for new, unseen inputs.
In other words, supervised learning is learning with supervision. We tell the model what the correct answer is during training, and the model tries to generalize from that experience.
How Supervised Learning Works
The basic supervised learning workflow looks something like this:
- Training Data: We start with a dataset that includes inputs (features) and outputs (labels).
- Model: We choose a model—a mathematical structure capable of learning patterns.
- Training: The model adjusts its internal parameters to minimize the difference between its predictions and the actual labels.
- Evaluation: We test the model’s ability to generalize using new, unseen data.
- Deployment: Once it performs well, the model is deployed into real-world scenarios.
Supervised learning algorithms aim to minimize a loss function—a mathematical measure of how far off their predictions are. Through optimization techniques like gradient descent, the model slowly “learns” to perform better.
Key Applications of Supervised Learning
Supervised learning has powered some of the most important advancements in technology:
- Image Recognition: Training models to recognize objects in photographs.
- Speech Recognition: Translating spoken words into written text.
- Email Spam Detection: Classifying emails as spam or not based on examples.
- Medical Diagnosis: Predicting diseases from diagnostic tests.
- Stock Market Prediction: Forecasting stock prices based on historical trends.
Any task where you have input-output pairs can, in theory, be tackled with supervised learning.
Types of Supervised Learning Problems
Supervised learning is broadly divided into two types:
- Classification: Predicting a category (e.g., is this email spam or not?).
- Regression: Predicting a continuous value (e.g., what will be the temperature tomorrow?).
Both classification and regression rely on the same fundamental principle: learning from labeled data.
Common Supervised Learning Algorithms
Here are some major players:
- Linear Regression: A foundational method for regression problems.
- Logistic Regression: A simple yet powerful classifier.
- Decision Trees: Models that split data into branches to make predictions.
- Support Vector Machines (SVM): Powerful classifiers that find the best boundary between categories.
- Neural Networks: Deep learning models that have revolutionized areas like vision and language.
Each has its strengths, weaknesses, and ideal use cases.
Strengths of Supervised Learning
- Accuracy: When enough labeled data is available, supervised learning can achieve very high performance.
- Predictability: Outputs are specific and interpretable.
- Scalability: Supervised learning scales well with data.
Weaknesses of Supervised Learning
- Data Dependency: Requires large amounts of labeled data, which can be expensive to obtain.
- Overfitting: Models may memorize training data rather than generalize.
- Bias: If the training data is biased, the model’s predictions will be biased too.
Thus, while supervised learning is powerful, it comes with limitations that must be respected and managed.
Unsupervised Learning: When Machines Learn Without a Map
The Essence of Unsupervised Learning
Now, picture a person dropped into a foreign country with no knowledge of the language, no maps, no guides. Yet, over time, they start to notice patterns—certain gestures mean certain things, certain buildings serve similar purposes.
This is unsupervised learning. In unsupervised learning, the machine receives only inputs, no outputs. It must discover the structure hidden within the data, finding patterns, groupings, anomalies—without explicit instruction.
Unsupervised learning is the art of discovery. It’s the machine’s innate sense of curiosity.
How Unsupervised Learning Works
In unsupervised learning:
- Training Data: We provide only input data, with no labels.
- Model: We select a model capable of identifying structure (e.g., clustering, dimensionality reduction).
- Learning: The model tries to group similar items, detect patterns, or simplify the data’s complexity.
Instead of minimizing a loss function tied to specific labels, unsupervised learning often focuses on maximizing similarity within groups and dissimilarity between groups, or on compressing the data while preserving its essential characteristics.
Key Applications of Unsupervised Learning
Unsupervised learning’s power lies in its ability to reveal hidden structures:
- Customer Segmentation: Grouping customers into segments based on behavior.
- Anomaly Detection: Finding fraud or rare events in large datasets.
- Recommendation Systems: Identifying similar users or products without explicit ratings.
- Document Clustering: Grouping news articles or research papers by topic.
- Genomic Data Analysis: Discovering patterns in genetic information.
In each case, unsupervised learning helps us organize and make sense of complex, unlabeled data.
Types of Unsupervised Learning Problems
Unsupervised learning can be broadly categorized:
- Clustering: Grouping similar items together (e.g., K-means clustering).
- Association: Discovering rules that describe relationships between variables (e.g., Market Basket Analysis).
- Dimensionality Reduction: Simplifying data by reducing the number of variables (e.g., Principal Component Analysis).
Each of these methods unveils different aspects of hidden data structures.
Common Unsupervised Learning Algorithms
Some of the key algorithms include:
- K-Means Clustering: A popular algorithm for grouping data into K clusters.
- Hierarchical Clustering: Building a tree of clusters.
- Principal Component Analysis (PCA): Reducing data dimensions while retaining variance.
- Autoencoders: Neural networks that compress and reconstruct data.
These algorithms, while less “famous” than their supervised counterparts, are no less powerful—and often far more mysterious.
Strengths of Unsupervised Learning
- No Labeled Data Needed: Saves massive time and effort.
- Discovery: Capable of uncovering hidden patterns.
- Flexibility: Can be applied to a wide range of data types.
Weaknesses of Unsupervised Learning
- Uncertainty: No clear “correct” output makes evaluation tricky.
- Complexity: Models may find patterns that are meaningless.
- Scalability: Some unsupervised methods struggle with very large datasets.
Thus, while unsupervised learning is a crucial tool for discovery, it must be wielded carefully.
Supervised vs. Unsupervised Learning: A Deep Comparison
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data | Requires labeled data | Works with unlabeled data |
| Goal | Predict output from input | Find hidden structures |
| Common Tasks | Classification, Regression | Clustering, Association, Dimensionality Reduction |
| Evaluation | Clear metrics like accuracy, precision, recall | Evaluation is subjective or based on internal metrics like cohesion |
| Example | Email Spam Detection | Customer Segmentation |
The difference, ultimately, boils down to the presence or absence of labeled data. But beneath this simple distinction lie philosophical differences about how machines approach knowledge itself.
Supervised learning is about mimicry and extrapolation: seeing examples and learning to predict.
Unsupervised learning is about curiosity and exploration: making sense of the unknown.
Both are essential. Both are powerful. Together, they give machines the tools to perceive, understand, and even create.
When to Use Supervised vs. Unsupervised Learning
Choosing between supervised and unsupervised learning depends on the problem at hand.
- If you have labeled data and a clear prediction goal, supervised learning is the way to go.
- If you are exploring data or looking for unknown patterns, unsupervised learning shines.
In real-world practice, hybrid approaches—like semi-supervised learning and self-supervised learning—are becoming increasingly popular, blurring the lines between the two.
Ultimately, the best choice depends on your data, your goals, your constraints, and your imagination.
The Future of Machine Learning: Blurring Boundaries
As machine learning evolves, the lines between supervised and unsupervised learning are becoming less rigid.
Newer approaches like self-supervised learning are gaining traction, especially in natural language processing and computer vision. In self-supervised learning, the model creates its own labels from the data—essentially turning unsupervised problems into supervised ones.
Techniques like contrastive learning (e.g., SimCLR, MoCo) allow models to learn powerful representations without labeled data, achieving breakthroughs once thought impossible.
Moreover, reinforcement learning, a third paradigm, blends elements of both supervision and autonomy, creating agents that learn through trial, error, and reward.
Thus, the future of machine learning is not a binary choice between supervised and unsupervised learning. It is a dynamic spectrum of strategies, each harnessing different aspects of information, discovery, and creativity.
Conclusion: The Art and Science of Learning
Supervised learning and unsupervised learning are not merely technical terms. They represent two fundamental modes of understanding the world.
- One through instruction, imitation, and guidance.
- One through observation, inference, and discovery.
In our own lives, we use both modes constantly. We learn some things because we are taught. We learn others because we notice.
Machines, too, are beginning to walk this path. Through supervised learning, they learn to follow. Through unsupervised learning, they learn to explore. Through the blending of both, they inch ever closer to genuine intelligence.
As researchers, developers, and dreamers, we stand at the threshold of an era where machines will not just store data or execute commands—they will understand, create, and perhaps, one day, even wonder.
The story of supervised and unsupervised learning is not just a technical tale. It is a chapter in the larger story of what it means to learn, to know, and to be alive.
And that story is only just beginning.





